Generate Random Training Points
The RBFLN neural network object
requires two sets of training points:
- one, "Deposits", that defines the presence
of the objects or conditions to be predicted (i.e.,
mineral occurrences)
- a second, "Non-Deposits, that defines the
absence of these objects (i.e., locations where mineral
occurrences are known not to occur).
The two sets of points (locations)
are combined as training data.
This second type of data set is
often not readily available so this function offers one way of
approximating such a data set. The idea is to generate a set of
points in parts of the study area where there is a very low
probability of the object occurring.
One possibility for applying the
function is to generate a probability map (response theme) using
the weights of evidence or logistic regression methods and then
generate a set of random points in areas of very low probability.
Another could be to simply use some data whose low values would indicate that
such a "Deposits" site would never occur. Then to generate the "Non-Deposits"
training sites, the following can be done:
- Select 'Generate Random
Training Points' from the ArcSDM3 menu.
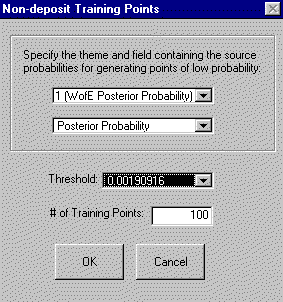 |
- In the 'Non-deposit
Training Points' dialog, specify:
- the name of the
raster to be used to generate the 'Non-Deposits' training sites.
- the field containing
the values (in this example, either
(WofE Posterior Probability or LR Posterior
Probability)
- a threshold value:
all of the points generated will fall in areas
that have values less than this value.
In this example, the
threshold should be lower than the prior probability. The
prior probability can be found in the third column of the
last row of the weights table associated with the
response theme, or can be reported by clicking the  button
in the deposit training point theme properties dialog.
This dialog is displayed by clicking the 'Properties'
button in the 'Analysis Parameters' dialog. button
in the deposit training point theme properties dialog.
This dialog is displayed by clicking the 'Properties'
button in the 'Analysis Parameters' dialog.
- enter the number of
points to be generated. The default is the number
of points in the deposit training point set.
- Click OK.
- When prompted,
specify the file name and location for the new
point shapefile. A point theme is created and
added to the top of the table of contents of the
active view.
|
General Application
The 'Generate Random Training
Points' function can use any integer grid theme in the active view. The minimum and maximum values in the
grid theme are reported as guidance and the default value is the
midpoint between these two. An evidence theme, whose low values indicated areas
where 'deposits' are highly unlikely to occur, can be used to define a
'non-deposits' training set. Another strategy might be to create several such
sets of 'non-deposits' and evaluate the differences between the resulting
models.
