This option is used to:
Section Contents:
This option performs the same weights calculations as those for individual evidential themes when you choose Calculate Theme Weights… but outputs only the W+, Contrast and Variance to tables with a format. Values in these summary tables are used to generate and append the output fields to the unique conditions attribute table. The output response themes are then produced by visualizing the unique conditions gird, symbolized according to attribute fields, such as posterior probability, posterior probability normalized by total uncertainty, and so on.
How the response theme is calculated
Each of the components is described in more detail following this section.
1. The user selects the evidential themes and attribute fields that contain the classes to analyze.
2. Weights, variances and contrast are calculated for each evidential theme and written to two tables, a weights table and a variances table.
3. The evidential themes are combined to make a unique conditions grid with an associated attribute table.
4. The evidential theme names (field names in the unique conditions grid attribute table) and classes occurring in each unique condition (record) are used to reference the weights and variances found in the weights and variances tables.
5. Using the previously calculated weights and variances, statistics, including the sum of weights, the posterior logit, posterior probability, uncertainty due to weights, uncertainty due to missing data and the total uncertainty are calculated for each unique condition and appended to the unique conditions grid attribute table.
6. The unique conditions grid is symbolized on the posterior probability attribute to create a response theme.
Inputs to Weights of Evidence Model - Themes
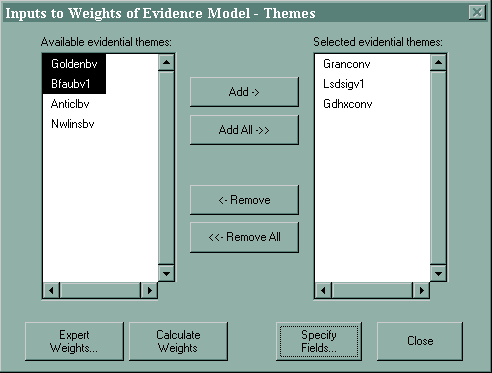
This dialog box is also used by the 'Check Conditional Independence...' function.
When you choose the Calculate Response Theme… option, the Inputs to Weights of Evidence Model - Themes dialog box is displayed. The names of all of the evidential themes found in the current View are displayed in the left hand column with the exception of the theme specified as the study area theme and any evidential themes that may have been previously moved to the right hand column. Weights will be calculated for all of the evidential themes appearing in the right hand column after the ‘Calculate Weights’ button on the Inputs to Weights of Evidence Model - Classes dialog (see below).
Note: For the Calculate Response Theme... option, evidential theme names should be kept to 12 characters, or to 10 characters if the pair-wise conditional independence test is run. Grids can have names containing up to thirteen characters. When making the unique conditions grid, temporary grids are named with the evidential theme name with an underscore appended. If this totals more than 13 characters, the name will be truncated. The proper theme name will still appear as an alias when the table is displayed. If the Identify tool is used, however, field names will not appear correctly. The pair-wise conditional independence test produces a set of dBase tables. The maximum number of characters a dBase field name can have is 10. While the aliases will appear correctly, the underlying field names will be truncated to conform with this standard.
To move evidential themes from the 'Available' to the 'Selected' column, click the buttons between the columns. For example, clicking Add-> will move the top evidential theme from the available column to the selected column if no available evidential themes are selected. If one or more of the available evidential themes have been selected (area highlighted), those themes will be moved when you click Add->. You can select an evidential theme by clicking on its name and you can add to the selection by holding down the Shift key and clicking on other evidential theme names.
When at least one evidential theme appears in the Selected… column, you can click the Specify Fields... button to specify display the Weights of Evidence Model – Classes dialog.
Inputs to Weights of Evidence Model – Classes

This dialog box is also used by the 'Check Conditional Independence...' function.
This dialog box displays the list of selected evidential themes, and to the right of each theme name, a combo box from which you can select the attribute field that contains the classes you want to base the analysis on. The default field in each combo-box is the numeric field farthest to the right in the theme's attribute table. If the default field is not the field you want to use, select another from the combo box.
When you have finished selecting the class fields, click 'OK'. This returns you to the Inputs to Weights of Evidence Model - Themes dialog. The 'Expert Weights' and 'Calculate Weights...' buttons on the dialog are now enabled. Click 'Calculate Weights...' to calculate weights and variances tables, and a response theme. To use the expert weights option, click 'Expert Weights...'. Refer to the Expert Weights Option below.
Weights of Evidence Table
The default name for the weights table is woe#.dbf. It has the following structure:
Evidential Theme – the names of the evidential themes are recorded in this column, one per row
Class Field – this records the name (not the alias) of the field that contains the classes for which the weights were calculated
W<#> – this is the template name for each of the fields containing the calculated weights, one for each class that occurs in any of the input evidential themes. If a class of the particular number does not occur in an evidential theme, its cell in that field will be blank.
Although it can be easier to read the table if a convention, such as 2 = presence and 1 = absence, any integer values can be used to identify classes. The number of classes that this table format can accommodate is very large, however it is recommended that multi-class evidential themes be limited to small number (typically not more than 5) to facilitate interpretation.
Contrast* – the difference between the highest weight and the smallest weight. Note that the 'true' contrast is defined only for binary themes.
Confidence – This is the studentized contrast*, which is the contrast divided by the standard deviation.
The last row – Several parameters are written to the last row of the weights table, as a convenient place to reference them. The name of the training point theme is written to the Evidential Theme field; the total number of training points is written to the first weight field; the total study area in units is written to the second weight field; and the prior probability (the total number of training points divided by the total study area) is written to the third weight field, or contrast* field. Note that these totals are not the values used in weights calculations for an evidential theme that contains areas with missing data.
The default name for the variances table is woevar#.dbf. It has the same structure as the weights table with the following exceptions:
| Next | Section Contents | Home |
Missing Data
If any of the data input data sets have areas where data are missing, this should be identified during the setting of weights of evidence analysis parameters. Any integer, including zero and negative numbers, may be used to identify areas of missing data. The same number, however, must be used for all data sets when creating a response theme or testing conditional independence (i.e., multiple data sets are being input). Refer to Integer that defines Missing Data.
If areas with missing data are defined using 'No Data' in a grid evidential theme, these areas will be filled in "on-the-fly" with the specified integer.
Arc-WofE handles missing data in the following way:
During the calculations of weights for an evidential theme, the total area is calculated as the total study area less any area where data are missing. The total number of training points is calculated as the total number of points in the study area less any points located in areas where data are missing.
If at least one input evidential theme contains missing data, a field named W<missing data integer> will be included in the weights table. If an evidential theme contains areas of missing data, the cell in the missing data class column will contain zero. If a theme has no missing data, the cell will be blank.
Uncertainty due to missing data
The extension requires that missing data be identified by a value (rather than 'No Data', for example) so that these areas can be captured in the unique conditions grid and attribute table. With the areas of missing data identified in each unique condition, a measure of uncertainty in the posterior probability can be calculated. Depending on the number of classes and evidential themes, and therefore number of unique conditions, and the number of themes in which data are missing, calculating uncertainty due to missing data may be time consuming. An estimation of the length of time it will take to calculate the uncertainty is made, and reported to the user if it is longer than one minute.
At the time of reporting, the user can choose to skip over the calculation of uncertainty due to missing data. The missing data and total uncertainty fields will be omitted from the unique conditions table. (Without the missing data component, total uncertainty will be equal to uncertainty due to weights.) The time estimate is based on processing times for a Pentium 133 notebook computer with 48 Mb of RAM. A more powerful computer, or a desk-top computer with the same parameters, will usually perform these calculations much faster. In some situations, such as processing data located across a network, may be considerably slower. The time required in most cases, however, is an over-estimate.
Expert Weights Option
This option allows the user to manipulate the weights that are generated for one or more of the evidential themes input to the model. Instead of using a set of training points to determine weights, the user specifies the model weights, either directly or by allocating the proportion of training points that fall in each class, or by specifying likelihood ratios for each class. This technique can be useful if the study area has not been previously explored, and a set of training points is small or not available. As each evidential theme is processed, the user is prompted by the following dialog:
You can set expert weights for up to 10 classes. If there are more than 10 classes in the class field you specified, you will be asked if you want to cancel the weights calculations or if you want to omit the evidential theme from your model.
On initial display, the dialog has the following settings:
Class – The classes found in the specified class field in the theme's attribute table.
% Points – The percentage of points allocated to each class. Initially this is set to be equal to the percentage of the total study area occupied by each class, resulting in weight values of zero.
Area – The percentage of the total study area occupied by each class.
Likelihood Ratio – The likelihood ratio calculated based on the specified percentage of points and percentage area for the class, as well as the total number of points, and total area. Initially this value is set to 1. The W+ value is the natural log of the likelihood ratio.
Weights – The W+ calculated for the current class, based on the specified percentage of points and percentage area for the class, as well as the total number of points, and total area. Initially this value is set to 0.
Inputting values
You can edit the % Points, Likelihood Ratios or Weights columns by clicking on the associated radio button, found in the upper left corner of the dialog and editing the values in the text lines. As you change any of these three values, the calculated values for the other two will be updated.
Note: Weights are always calculated based on the % Points displayed in the dialog.
When you close the dialog, the total percentage of points must sum to 100%. You can automatically adjust your percentages so they total 100 by clicking the 'Normalize' button.
Reading Weights from an Existing Table
You can read weights that have been previously calculated and written to a weights table. To do this:
You can then modify the weights, and when you are done, click 'OK' to continue with calculations.
Except for the user interaction with this dialog, all of the calculations and output are the same as for the 'regular' weights option.
| Next | Section Contents | Home |
Response Theme
The Response Theme is an integer Grid Theme and its attribute table. The grid can be described as a unique conditions grid. Its cell values range from 1 to n, each integer identifying a unique condition or combination of cells values found in the input evidential themes. The grid and its attribute table are created by a single Avenue request, (Combine), that combines a set of grids.
The table created by the Combine request automatically has a Value and Count fields, plus one field for each input evidential theme. The field alias for each of these fields corresponds to the name of the evidential theme. (Note that if you use the Identify tool to view the attribute values for any particular cell in the response theme, the evidential theme names (field names) will typically have an underscore following the name. The underscore was used to differentiate the temporary grids from the original evidential theme grid.)
The values in the evidential theme fields contain the class values that occur in each unique condition (represented by a record or row).
Arc-WofE calculates and appends the following for each unique condition:
Training Points – number of training points occurring in that condition
Area (sq. m) – area, measured in square metres
Posterior Probability – the posterior logit converted to a probability
Posterior Logit – the sum of weights added to the prior logit
Sum of Weights – the sum of the weights for each evidential theme class occurring in the unique condition
Uncertainty – the uncertainty due to the calculation of weights (standard deviation)
Missing Data – uncertainty due to missing data (standard deviation)
Total Uncertainty – the combined uncertainty due to weights and due to missing data (standard deviation)
Refer to the equations used to calculate weights and probabilities.
As with the other tables produced by Arc-WofE, the aliases listed above may differ from the underlying field names:
Field Alias |
Field Name |
| Training Points | TrngPoints |
| Area (sq. m) | Area_sqm |
| Posterior Probability | Post_Prob |
| Posterior Logit | Post_Logit |
| Sum of Weights | Sum_Weights |
| Uncertainty | Uncertainty |
| Missing Data | Msng_Data |
| Total Uncertainty | Tot_Uncrty |
How the weights table is used to calculate posterior probabilities
One unique condition, or record, in the unique conditions table is processed at a time. For each evidential theme included in the response theme, determined by reading the field names, the class occurring in that unique condition is read. The evidential theme name is then located in the weights table, and the weights calculated for that class is read and added to the sum of weights. The correct weight is identified by the field name in the weights table, i.e. the weight for class 4 in Theme 3 is found in the cell located at the intersection of the record where 'Theme 3' is written in the Evidential Theme field, and the field named W4.
Options to run CI test and Associate probabilities with point theme functions
Once the response theme has been calculated, an option is given to run the pair-wise conditional independence test. Running the test at this point is slightly faster than running it from the menu option because the unique conditions table has already been created for the response theme and is used as the basis for the test. Users are also provided with the option to create a table that writes the probabilities at the location of each point in the training point theme along the coordinates of each point. Please refer to Associate Responses with Points.
Overall Test of Conditional Independence
Once the response theme is complete, Arc-WofE reports a ratio that can be used as an overall assessment of conditional independence among your data sets. This ratio is calculated as follows:
The product of area and posterior probability summed over each unique condition is the number of points predicted by the model. A ratio is calculated by dividing the actual number of training points input to the model by this predicted number of points. This ratio will always be between 0 and 1. A value of 1 (never occurs in practice) indicates conditional independence among the evidential themes used in the model. Values much smaller than 1 indicate a conditional independence problem.
If you choose to run the pair-wise test of conditional independence when prompted, the overall test result will be written to the last row of the probability table.
| Next | Section Contents | Home |
Symbolization of the Response Theme
The Response (Grid) Theme (actually the unique conditions grid) is automatically added to the current View and symbolized based on the Posterior Probability attribute, using 7 classifications defined by ArcView’s natural breaks method. (Fewer classifications are applied if there are fewer than 7 records or values in the response theme attribute table.)
The following is the RGB colour palette used:
| Classification | RGB Code |
| 1 | 0,106,255 |
| 2 | 0,233,255 |
| 3 | 85,255,0 |
| 4 | 191,255,0 |
| 5 | 255,212,0 |
| 6 | 255,106,0 |
| 7 | 255,0,0 |
For options on symbolizing the reponse theme, see the section describing symbolization tools.
Making a Confidence Map: Normalizing the Posterior Probability by the Total Uncertainty
You can also normalize the probability values by Uncertainty (due to weights) if, for example, you did not elect to calculate uncertainty due to missing data.
Make the Response Theme you want to normalize active.
Double-click the theme’s legend to open the legend editor dialog.
From the ‘Normalize by:’ combo box, select ‘Total Uncertainty’.
Click ‘Apply’.
Click the ‘X’ button to close the dialog.
You can change the Theme’s name to reflect the legend by selection Properties from the Theme menu.
| Section Contents | Home |